
One possible way to evade V2Ray deep neural network traffic classifier is to encode the network traffic with adversarial noise.
To simplify the problem, let’s have the following assumptions:
- We own the classifier model.
- We are oracles. Thus, we know the first 16th non-empty TCP payload traffic ahead.
- We can apply adversarial noise without any restrictions.
You can argue that none of the assumptions are valid in our case. But we may figure out how to remove our assumption one-by-one later. First, I want to do a PoC on the adversarial example idea by trial and error.
Nobody proposed an adversarial example to attack the machine learning model until a deep neural network can reach unprecedented high accuracy in image classification. The math behind generating adversarial examples is straightforward.
Let say we have a binary network traffic classifier

where input X is the network traffic and scalar ![Y \in [0, 1]](https://s0.wp.com/latex.php?latex=Y+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Because we have a powerful classifier like almighty God (it has been proven).
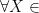
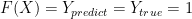

Our goal is to find adversarial noise 

Because this is a binary classifier. The targeted attack is the same as the untargeted attack. If this were multi-class classifier, you could perform targeted attack by specifying 
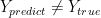
In DNN, 
The usual approach is to use the gradient to approximate the adversarial noise. I have tried Fast Gradient Sign Method (FGSM), DeepFool and Jacobian-based Saliency Map (JSMA). I found FGSM is the most effective one for the binary classifier. I will explain the math behind it below.
When train the DNN classifier, we also define loss function 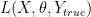


Now we do the opposite thing for generating adversarial examples. We already have a trained model. Thus, we have a set of fixed values for the network parameters 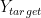
We want to minimize the loss function by finding input X. So we have the following optimization problem to solve:
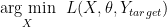
We use a similar optimization approach — gradient descent but on the input 

We want the adversarial noise as minimal as possible. FGSM suggests that the size of the gradient 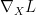
How can we come up a universal scalar value? It depends on your input 

adversarial noise =
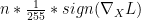
In practice, I found FGSM approach is better than DeepFool and JSMA.
- Both DeepFool and JSMA need to compute forward gradient on
- FGSM requires less computation than DeepFool and JSMA. FGSM only need to compute the gradient once. Then loop model inference to get the proper scalar. The other two requires multiple gradient calculation in the loop.
Now let me show you show code and image. I published the Python notebook in my Github. You can replicate my experiment if you collect network traffic by yourself.
I plotted the adversarial noise as an image for input batch = 32. The color red is 1, green is -1, blue is 0, black is the borderline drawn between examples.

I found that:
- There is always a blue line in the last packet in each example. It seems that the 16th packet is irrelevant.
- From my eyeballs, there are common patterns in the adversarial noise. This suggests that a universal adversarial noise that applies to all input may exist.
So far so good. In theory, we can defeat the DNN classifier by adding adversarial noises. The next step is to remove the assumptions one-by-one so that make it possible in our real-world application.
Great content! Super high-quality! Keep it up! 🙂
Good Job